Super-Resolution Research · Part 2
Super-Resolution Research, Part 2: Why Resizing Libraries Disagree
Same image, same target size, four libraries, wildly different results. A systematic comparison reveals up to 21 dB PSNR differences between resizing implementations -- and why this undermines SR benchmark reproducibility.
Originally written 2022-07
I assumed, as I think most people do, that “bicubic resize to 100x100” was a deterministic operation — that the words meant the same thing regardless of which library executed them. This turned out to be wrong in a way that has real consequences for anyone who evaluates image processing models, and particularly for the super-resolution community where fractions of a dB in PSNR separate “state of the art” from “not publishable.”
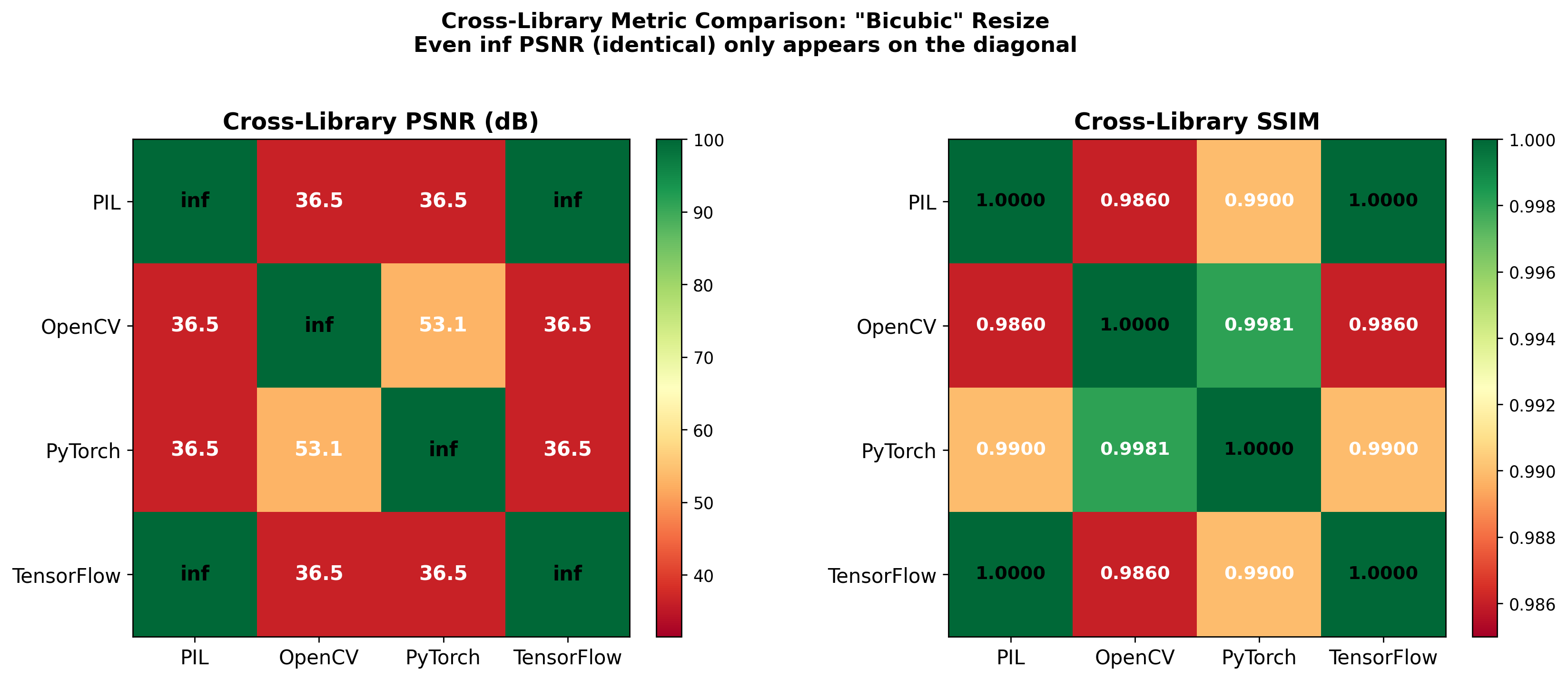
The discovery was accidental. During my CS 497 independent study in summer 2022, I was building a unified image processing pipeline for super-resolution research and needed a resizing function that worked consistently across different parts of the codebase. I had PIL in one module, OpenCV in another, and PyTorch in the training loop. I assumed they were interchangeable for bicubic resizing. They are not. When I finally compared their outputs on the same image, the PSNR between PIL’s output and OpenCV’s output was 21 dB — a number large enough that if it appeared in a benchmark table, you would conclude the model had failed. That realization pulled me into a systematic investigation that eventually led to finding a bug in clean-fid .
The Experiment
I built a make_resizer function that wraps each library’s resizing behind a common interface so the only variable is the library itself:
def make_resizer(library, quantize_after, filter, output_size):
"""
Unified resizing interface.
library: "PIL", "OpenCV", "PyTorch", or "TensorFlow"
quantize_after: if False, return float32; if True, return uint8
filter: "bicubic", "bilinear", "lanczos", etc.
output_size: (width, height) tuple
"""
if library == "PIL" and quantize_after:
def func(x):
x = Image.fromarray(x)
x = x.resize(output_size, resample=Image.BICUBIC)
x = np.asarray(x).clip(0, 255).astype(np.uint8)
return x
elif library == "OpenCV":
def func(x):
x = cv2.resize(x, output_size, interpolation=cv2.INTER_CUBIC)
x = x.clip(0, 255)
if quantize_after:
x = x.astype(np.uint8)
return x
elif library == "PyTorch":
def func(x):
x = torch.Tensor(x.transpose((2, 0, 1)))[None, ...]
x = F.interpolate(x, size=output_size, mode=filter,
align_corners=False)
x = x[0, ...].cpu().data.numpy().transpose((1, 2, 0))
x = x.clip(0, 255)
if quantize_after:
x = x.astype(np.uint8)
return x
elif library == "TensorFlow":
def func(x):
x = tf.constant(x)[tf.newaxis, ...]
x = tf.image.resize(x, output_size, method=filter)
x = x[0, ...].numpy().clip(0, 255)
if quantize_after:
x = x.astype(np.uint8)
return x
return funcI ran this on two inputs. First a synthetic image for the controlled case, then a natural image for the realistic case.
Synthetic Image: A Circle
A white 128x128 image with a black circle drawn on it. Simple geometry, no texture ambiguity. Resized to 16x16 with bicubic interpolation. Comparing PIL against PyTorch:
| Metric | Value |
|---|---|
| PSNR | 24.25 dB |
| SSIM | 0.758 |
24 dB PSNR between two “bicubic” resizes of a circle. The synthetic case at least has the excuse that 16x16 is extremely small and edge effects dominate at that scale, but 24 dB is still a number that would raise alarms in any other context.
Natural Image: The Baboon
The real test. baboon.bmp from Set14, 500x480 pixels, resized to 100x100 with bicubic interpolation. Comparing PIL against OpenCV:
| Metric | Value |
|---|---|
| PSNR | 21.00 dB |
| SSIM | 0.673 |
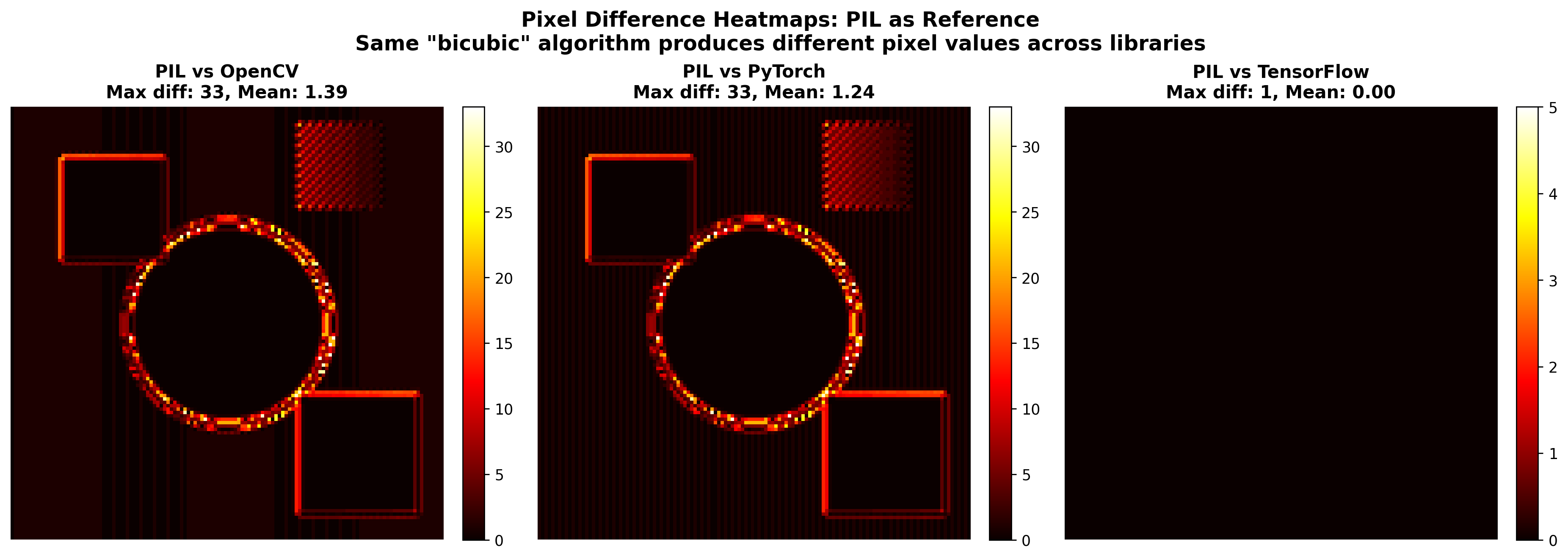
21 dB PSNR. If you saw 21 dB in a super-resolution benchmark, you would conclude the model had produced garbage. This is worse than many naive upscaling baselines. And yet both images are “correct” bicubic downscalings of the same source — they just come from different libraries with different ideas about what “bicubic” means.
Sanity Check: Is It the Loading?
Before anyone suspects the discrepancy originates in image loading rather than resizing, I verified explicitly. The same baboon loaded through PIL and OpenCV (with BGR-to-RGB conversion):
| Metric | Value |
|---|---|
| PSNR | 100 dB (identical) |
| SSIM | 1.0 |
Byte-identical arrays. The disagreement is entirely in the resize operation.
Why Four Libraries Produce Four Different “Bicubic” Results
Bicubic interpolation sounds like a single well-defined mathematical operation. It is not. It is a family of algorithms with implementation-specific choices at every level, and each library has made different choices.
Kernel Coefficients
Bicubic interpolation uses a family of kernels parameterized by a constant :
PIL uses (the Catmull-Rom spline). OpenCV uses . PyTorch uses . All three are called “bicubic” in their respective APIs. All three weight neighboring pixels differently. Those different weightings produce different interpolated values at every single output pixel, and the differences accumulate across the entire image. (The naming is technically correct — they are all cubic polynomials — but the practical implication is that “bicubic” is a family name, not a specification, and treating it as a specification is where the trouble starts.)
Coordinate Mapping
When resizing from to , each output pixel must map back to a floating-point location in the input. There are two conventions, and the choice shifts the entire sampling grid:
Align corners (used by some PyTorch modes):
Half-pixel offset (used by PIL, TensorFlow default):
The difference looks trivial on paper but it shifts every single sampling point, which means every interpolated value changes. PyTorch at least exposes this explicitly via the align_corners parameter; other libraries simply make the choice for you and do not mention it in the docstring.
Anti-aliasing
When downscaling, high-frequency content above the new Nyquist frequency should be filtered out to prevent aliasing. PIL applies an anti-aliasing prefilter by default for downscaling. OpenCV’s cv2.resize does not — it interpolates at the output grid points without any prefiltering, which means aliased high-frequency content survives into the output and changes the pixel values. For images with fine texture (like the baboon’s fur), this difference alone accounts for a significant portion of the 21 dB gap.
Edge Handling and Numerical Precision
What happens when the interpolation kernel extends beyond the image boundary? Options include reflection, zero-padding, clamping to the nearest edge pixel, or wrapping. Different libraries make different choices, and the effects propagate inward from the borders. On top of this, some libraries compute interpolation in float32, others in float64, and the intermediate precision affects rounding after quantization to uint8.
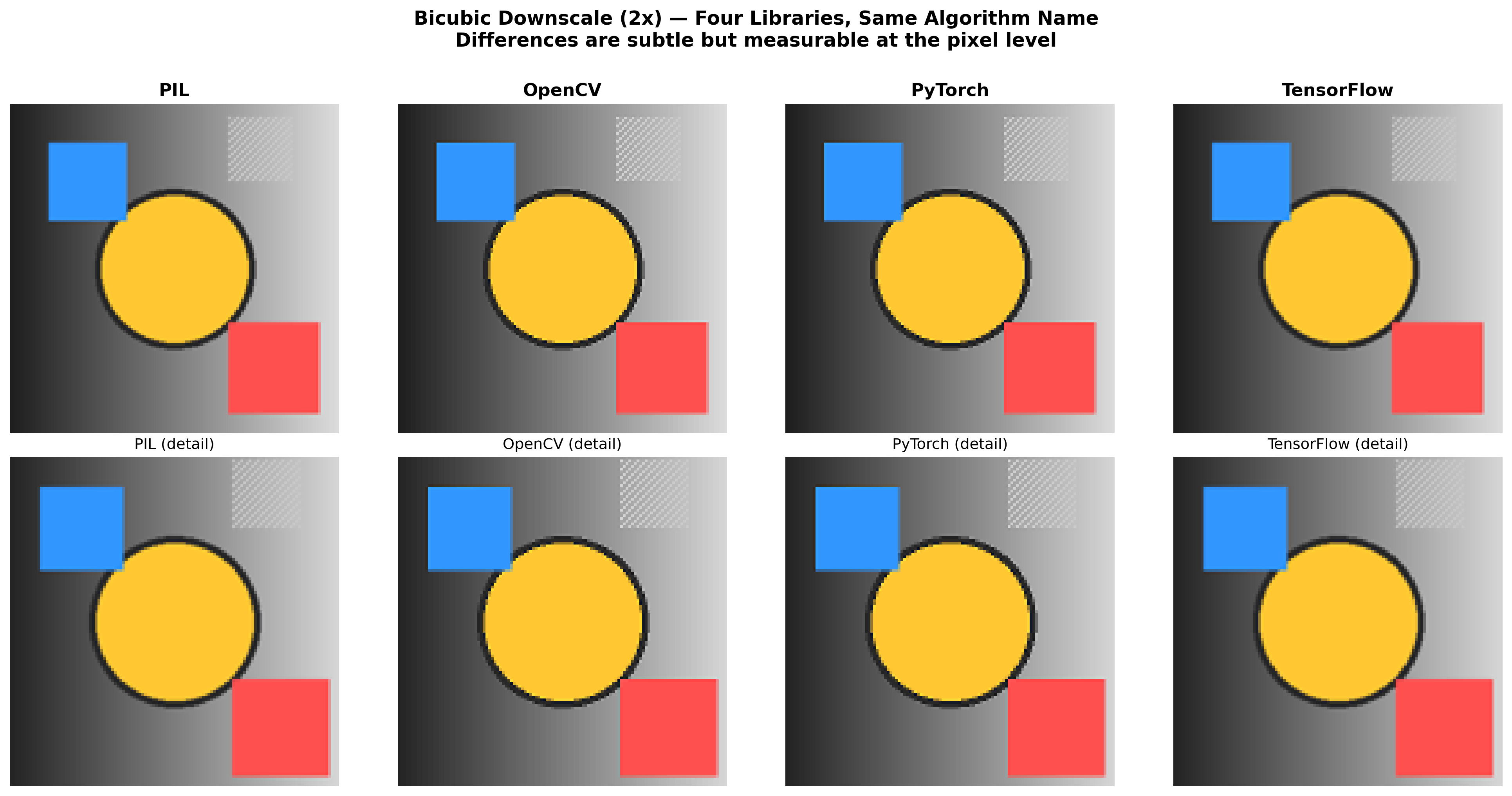
The Visual Evidence
When you look at the four resized versions side by side, the differences are not obvious at a casual glance. They all look like the baboon, resized. But examine the details:
PIL produces the sharpest result with the most pronounced ringing artifacts around high-contrast edges — the fur strands in the baboon’s face have crisp, well-defined boundaries. OpenCV is smoother overall, with less ringing but also less texture detail; the transition between nose and surrounding fur is more gradual. PyTorch sits between the two in sharpness, with a subtly different color balance at high-contrast boundaries due to its different kernel parameter. TensorFlow produces the smoothest result with noticeably less high-frequency detail.
None of them are “wrong.” They are all valid interpretations of “resize this image using bicubic interpolation.” The problem is that they are measurably, quantifiably different by an amount that dwarfs the improvements papers claim as significant.
What This Means for SR Research
Consider the standard super-resolution evaluation:
- Take high-resolution image
- Downscale to using some library
- Run SR model:
- Compute
If Paper A uses PIL for step 2 and Paper B uses OpenCV, they are solving different problems. Their low-resolution inputs are different images, their models learn different mappings, and comparing their PSNR numbers is comparing results on different benchmarks while pretending they are the same benchmark. I found this because I was trying to reproduce SRCNN results and kept getting different numbers depending on which library handled the preprocessing. The original SRCNN paper used MATLAB’s imresize, which has its own kernel and coordinate mapping that none of the standard Python libraries replicate by default.
This investigation is also what led me to examine clean-fid more closely, where I discovered and fixed a width/height swap that had gone unnoticed because the default FID computation uses square images — and for square images, swapping width and height is a no-op.
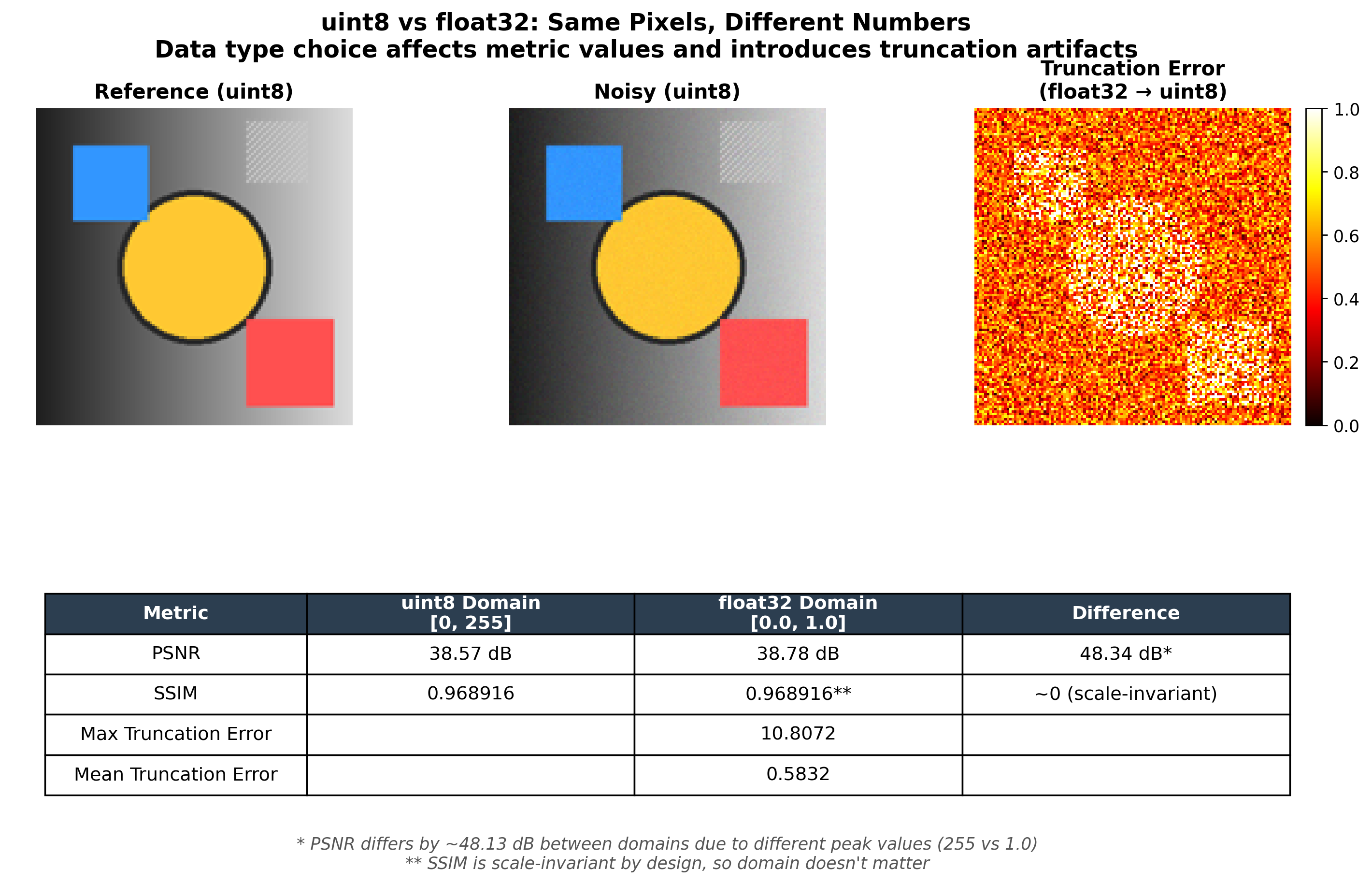
TIL: uint8 vs float32 Produces a ~48 dB PSNR Difference
During these experiments I discovered that the quantize_after parameter — whether you convert to uint8 immediately after resizing or keep float32 — has an enormous effect on metrics that I had not anticipated.
Rounding float32 values to the nearest integer introduces an error of up to 0.5 per channel per pixel. For 8-bit images:
In practice the MSE is lower than the worst case, so you get values in the 54-60 dB range. The implication: if your training pipeline uses float32 internally but your evaluation quantizes to uint8, or vice versa, you have introduced a systematic bias that has nothing to do with your model. Always be explicit about data types. If you compute PSNR on float32, both arrays must be float32 with the same normalization.
TIL: PIL Width/Height vs NumPy Height/Width
Another convention mismatch I kept tripping over during this work:
img_pil = Image.open('comic.bmp')
print(img_pil.size) # (250, 361) -- (width, height)
img_np = np.asarray(img_pil)
print(img_np.shape) # (361, 250, 3) -- (height, width, channels)PIL puts width first. NumPy puts height first. OpenCV follows NumPy’s convention. If you pass PIL’s .size tuple directly to a NumPy reshape or use it where height-first is expected, you silently transpose your image — and for square images, the transposition is invisible because width equals height. This is exactly why the width/height swap I found in clean-fid shipped undetected: the default FID computation size is 299x299, and nobody tested with non-square images.
What Should Change
The SR community has gradually become aware of this, though awareness has not yet translated into consistent practice. Some newer datasets provide pre-downscaled images so everyone evaluates against the same LR inputs. DIV2K does this. But many older benchmarks — Set5, Set14, BSD100 — leave the downscaling to the researcher, and papers still report results on these sets without specifying their exact preprocessing.
If I could mandate four things:
- Specify the library and version used for resizing. “Bicubic downscaling” is not a specification; it is a family of algorithms.
- Provide pre-downscaled images as part of the benchmark, or publish the exact script.
- Report the resizing parameters: kernel type ( value), anti-aliasing, coordinate mapping, output data type.
- Use a reference implementation that everyone agrees on. The clean-fid library’s “clean” resize mode is the right idea — a standardized, explicitly defined preprocessing pipeline.
Until then, treat cross-paper PSNR comparisons with suspicion, especially when the preprocessing details are unspecified. A 0.5 dB improvement might be a genuine architectural advance, or it might be a different resize kernel. Without the methodology section to distinguish between the two, the number is decoration.
Reproducing This
If you want to verify these results yourself:
import numpy as np
import cv2
from PIL import Image
import torch
import torch.nn.functional as F
# Load image
img = cv2.imread('baboon.bmp')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Resize with PIL
pil_img = Image.fromarray(img)
pil_resized = np.asarray(pil_img.resize((100, 100), Image.BICUBIC))
# Resize with OpenCV
cv_resized = cv2.resize(img, (100, 100), interpolation=cv2.INTER_CUBIC)
# Resize with PyTorch
pt_tensor = torch.Tensor(img.transpose((2, 0, 1)))[None, ...]
pt_resized = F.interpolate(pt_tensor, size=(100, 100),
mode='bicubic', align_corners=False)
pt_resized = pt_resized[0].numpy().transpose((1, 2, 0)).clip(0, 255)
# Compare PIL vs OpenCV
mse = np.mean((pil_resized.astype(float) - cv_resized.astype(float)) ** 2)
psnr = 10 * np.log10(255**2 / mse)
print(f"PIL vs OpenCV PSNR: {psnr:.2f} dB") # ~21 dBThe exact values will vary slightly depending on your library versions and the source image. The magnitude of disagreement will not: double-digit dB differences for natural images with texture.
This is part 2 of a 3-part series on image quality metrics. Part 1 covers why PSNR is a broken metric for perceptual quality with a 1-pixel shift experiment, and Part 3 documents the bug I found and fixed in clean-fid .