Super-Resolution Research, Part 8: The clean-fid Bug That Hid Behind Square Images
While investigating resizing inconsistencies, I discovered a width/height swap in clean-fid, a widely-used FID computation library. The bug was invisible for square images -- and the default size is 299x299. PR #28, merged upstream.
- Author
- Shlomo Stept
- Published
- Updated
- Note
- Originally written 2022-04
Finding a Width/Height Swap in clean-fid That Hid Behind Square Images
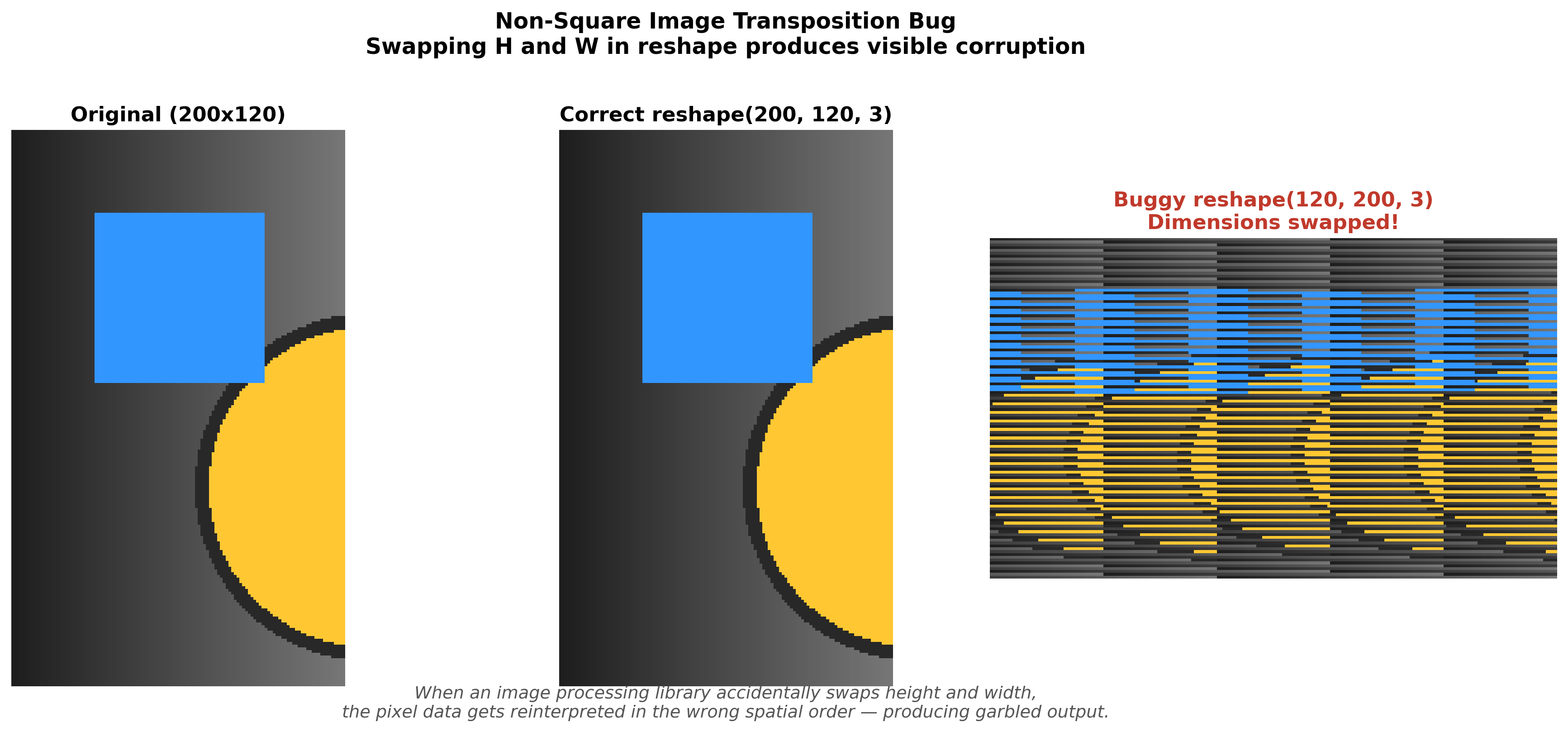
I did not set out to find a bug in clean-fid. I was trying to figure out why my PSNR numbers were wrong, which led me to investigate why different resizing libraries produce different results, which led me to use clean-fid as a reference implementation for “correct” resizing, which led me to resize a non-square image and get output that was visibly distorted. The bug was a single transposition — .reshape(s1, s2, 1) where it should have been .reshape(s2, s1, 1) — and it had survived in a library used by researchers worldwide because the default FID computation size is 299x299, and for square images, swapping width and height changes absolutely nothing.
I submitted PR #28 , merged on April 21, 2022. One line changed, two variables swapped.
What clean-fid Does and Why It Matters
Frechet Inception Distance is the standard metric for evaluating generative image models — it measures how similar a distribution of generated images is to a distribution of real images by comparing their feature representations in a pretrained Inception-v3 network. Lower FID means the generated distribution is closer to the real one. The problem, which should sound familiar if you have read the resizing disagreement post , is that different FID implementations produced different scores for the same images because they used different preprocessing pipelines. Gaurav Parmar and collaborators at CMU built clean-fid to solve exactly this problem. Their paper, “Aliased Resizing and Surprising Subtleties in GAN Evaluation” , documented the preprocessing inconsistencies across existing FID implementations and provided a standardized library with a “clean” resizing mode and backward-compatible “legacy” modes.
The library became widely adopted. Researchers used it as the canonical tool for computing FID, trusting it to handle the preprocessing correctly so they could focus on the generative model itself. Which makes what I found darkly amusing: the library built specifically to fix preprocessing inconsistencies in metric computation had its own preprocessing inconsistency, hiding in a reshape call that nobody had reason to test with non-square images.
The Bug
The affected code lives in resize.py, in the make_resizer function. Here is the relevant branch — PIL with quantize_after=False, the “clean” mode:
def make_resizer(library, quantize_after, filter, output_size):
# ... other branches ...
elif library == "PIL" and not quantize_after:
name_to_filter = {
"bicubic": Image.BICUBIC,
"bilinear": Image.BILINEAR,
"nearest": Image.NEAREST,
"lanczos": Image.LANCZOS,
"box": Image.BOX
}
s1, s2 = output_size
def resize_single_channel(x_np):
img = Image.fromarray(x_np.astype(np.float32), mode='F')
img = img.resize(output_size, resample=name_to_filter[filter])
return np.asarray(img).clip(0, 255).reshape(s1, s2, 1) # <-- here
def func(x):
x = [resize_single_channel(x[:, :, idx]) for idx in range(3)]
x = np.concatenate(x, axis=2).astype(np.float32)
return xThe function unpacks output_size as s1, s2 = output_size, where output_size is (width, height) following PIL’s convention. Then it reshapes the resized array as .reshape(s1, s2, 1) — which means .reshape(width, height, 1).
But NumPy arrays follow (height, width, channels). The reshape should be .reshape(s2, s1, 1) — that is, .reshape(height, width, 1).
The fix:
# Before:
return np.asarray(img).clip(0, 255).reshape(s1, s2, 1)
# After:
return np.asarray(img).clip(0, 255).reshape(s2, s1, 1)One line. The most consequential variable swap I have ever submitted.
Why Nobody Noticed
This is, to me, the most instructive part of the whole story, because it explains not just why this specific bug survived but why an entire category of dimension-related bugs survives in image processing code generally.
The default FID computation resizes images to 299x299 — the input size of Inception-v3:
def build_resizer(mode):
if mode == "clean":
return make_resizer("PIL", False, "bicubic", (299, 299))When output_size = (299, 299), we get s1 = 299, s2 = 299. The reshape becomes .reshape(299, 299, 1), which is identical whether you meant (width, height) or (height, width). The transposition disappears into the symmetry of the square. Every standard FID computation uses 299x299. Every test anyone ever ran used square outputs. The bug only becomes visible when you resize to a non-square target, which is not the default use case for FID but is a perfectly valid use of the make_resizer function that the library exports as a general-purpose utility.
This is a general pattern worth remembering: any bug involving transposed spatial dimensions will be invisible in the square case. If your test images are square, if your default output sizes are square, if your quick sanity checks use np.zeros((100, 100, 3)), you will never catch a width/height swap through testing alone. The bug exists in a region of the parameter space that your tests do not visit.

How I Found It
The discovery came at the end of a chain of investigations, and the chain matters because it illustrates something about how methodical debugging surfaces bugs in unexpected places.
Step 1: My PSNR numbers did not match published results. I was implementing SRCNN for my CS 497 independent study and my evaluation metrics differed from the paper’s by more than I could explain. Rather than blaming my model, I questioned the metric — which felt like a strange thing to do at the time, since PSNR is just arithmetic, but turned out to be the right instinct.
Step 2: I discovered that resizing libraries disagree. Building a systematic comparison revealed that PIL, OpenCV, PyTorch, and TensorFlow produce different outputs for the “same” bicubic resize, differing by up to 21 dB PSNR . This explained part of my number mismatch.
Step 3: I used clean-fid as a reference implementation. Since clean-fid was designed to standardize image preprocessing for metric computation, I trusted its make_resizer function as ground truth for my comparison pipeline. (In retrospect, “trusted” is doing a lot of heavy lifting in that sentence.)
Step 4: clean-fid’s output looked wrong on non-square images. When I resized baboon.bmp to 140x100 using clean-fid’s “clean” mode, the output was visibly distorted — stretched along the wrong axis. I stared at it for a few seconds, opened the source code, found the reshape line, and understood immediately.
The whole arc — from debugging my own metrics, through library disagreement, to finding a bug in the library I was using as my gold standard — happened over a few weeks in April 2022. Each step followed from the previous one because I refused to accept discrepancies without explaining them. I was not looking for bugs in other people’s code. I was looking for the source of a 1 dB discrepancy in my own results.
The concrete evidence:
Case 1: Original clean-fid code, output_size=(140, 100)
- With
quantize_after=True: image looks correct (140 wide, 100 tall) - With
quantize_after=False: image looks distorted — transposed
Case 2: Fixed code (.reshape(s2, s1, 1)), output_size=(140, 100)
- With
quantize_after=True: image looks correct (unchanged — this branch does not use the manual reshape) - With
quantize_after=False: image looks correct
The quantize_after=True branch was unaffected because it calls Image.resize followed by np.asarray(), which naturally produces (height, width) arrays. The quantize_after=False branch processes each channel separately and manually reshapes the result, and that reshape had the dimensions reversed.
img = Image.open('baboon.bmp')
img_np = np.asarray(img)
# Original version
resizer_original = make_resizer('PIL', False, 'bicubic', (140, 100))
result_original = resizer_original(img_np)
# Corrected version
resizer_fixed = make_resizer_fixed('PIL', False, 'bicubic', (140, 100))
result_fixed = resizer_fixed(img_np)I also verified with square images to confirm the fix changed nothing for existing workflows:
output_size=(100, 100):
- Original: correct (because 100=100)
- Fixed: identical output
Backward-compatible. Safe. One line.
The Pull Request
PR #28 , one-line diff:
- return np.asarray(img).clip(0, 255).reshape(s1, s2, 1)
+ return np.asarray(img).clip(0, 255).reshape(s2, s1, 1)Merged April 21, 2022. The maintainers recognized the issue immediately once it was pointed out — it is one of those bugs that is obvious in hindsight and invisible in foresight because the standard use case masks it entirely.
What I Took Away
Metric code gets less scrutiny than it deserves. When you write a neural network, you test it: does the loss decrease? Do the outputs look reasonable? Does it converge? Metric code produces a number, and if the number falls in the expected range — FID scores typically run from about 1 to 300 — nobody questions the implementation. There is no gradient signal telling you the metric is computing the wrong thing. clean-fid was developed by careful researchers who wrote an entire paper about evaluation correctness, and their codebase still harbored a dimension swap because the default parameters masked it. If that does not make you slightly nervous about your own metric code, it probably should.
Square defaults are a trap. Any issue involving transposed dimensions vanishes in the square case. Image classification networks default to square inputs (224x224, 299x299). Quick sanity checks use square test arrays. If you write code that handles spatial dimensions, test with non-square inputs. Not as an afterthought — as a mandatory test case. A 100x100 test passes silently; a 140x100 test catches the problem on the first run.
The PIL/NumPy convention mismatch keeps biting people. PIL uses (width, height). NumPy uses (height, width). Everyone knows this. And yet it keeps surfacing in production code, research code, and libraries written by people who absolutely know better, because the mismatch is just subtle enough to slip past code review when the variable names are s1, s2 instead of w, h:
# Ambiguous:
s1, s2 = output_size
# Clear:
w, h = output_size
# ...
return np.asarray(img).clip(0, 255).reshape(h, w, 1)With explicit names, the reshape reads as “height, width, 1” and you can verify it matches NumPy’s convention at a glance.
Cross-validating code paths catches things unit tests miss. I found this bug because clean-fid had two code paths for the same operation: quantize_after=True and quantize_after=False. The first was correct because it relied on PIL’s natural output shape. The second had the manual reshape bug. Comparing both paths on a non-square image revealed the discrepancy instantly. When you have multiple implementations of the same functionality, running them against each other on edge cases is one of the most effective testing techniques I know of.
Impact
PR #28 corrected the non-square resize path in a library used as a dependency in numerous research codebases. For the default 299x299 FID computation, the bug was latent — present in the code but producing correct output by coincidence of symmetry. For anyone using the library’s make_resizer for non-standard output sizes, the fix eliminated silent data corruption.
If a library that was specifically designed for correct image preprocessing can ship a dimension swap that survives until someone happens to test with a non-square image, it is worth asking what similar bugs might be hiding in preprocessing pipelines that were not designed with anywhere near the same level of care. My recommendation, which I will keep repeating because it keeps being relevant: test with non-square images. Test with non-square images. Test with non-square images.
This is part 3 of a 3-part series on image quality metrics. Part 1 demonstrates why PSNR is a broken perceptual metric with a 1-pixel shift experiment, and Part 2 documents systematic disagreement between resizing libraries . Together they trace a single investigation — from a PSNR number that did not match, through library inconsistencies, to a bug in the tool I was using to check everything else.