Building Deep Learning from Scratch · Part 3
Building Deep Learning from Scratch, Part 3: A Transformer in PyTorch
A complete walkthrough of implementing the encoder-decoder Transformer architecture from 'Attention Is All You Need' — the math, the code, the architecture decisions, and lessons from training 68 epochs of German-to-English translation.
Originally written 2023-02
There is a difference between understanding a paper and implementing it. I thought I understood “Attention Is All You Need” after reading it twice and watching a few YouTube walkthroughs. Then I tried to build one from scratch, and I discovered that understanding the architecture diagram is maybe 30% of the work. The remaining 70% is tensor shapes, masking logic, and getting every dimension to line up across a six-layer encoder-decoder stack.
This post walks through my full implementation of the Transformer for German-to-English translation on the Multi30k dataset. I cover the architecture, the math, the PyTorch code, and the refinements I identified during a comprehensive code audit — each of which deepened my understanding of how these models actually work at the implementation level.
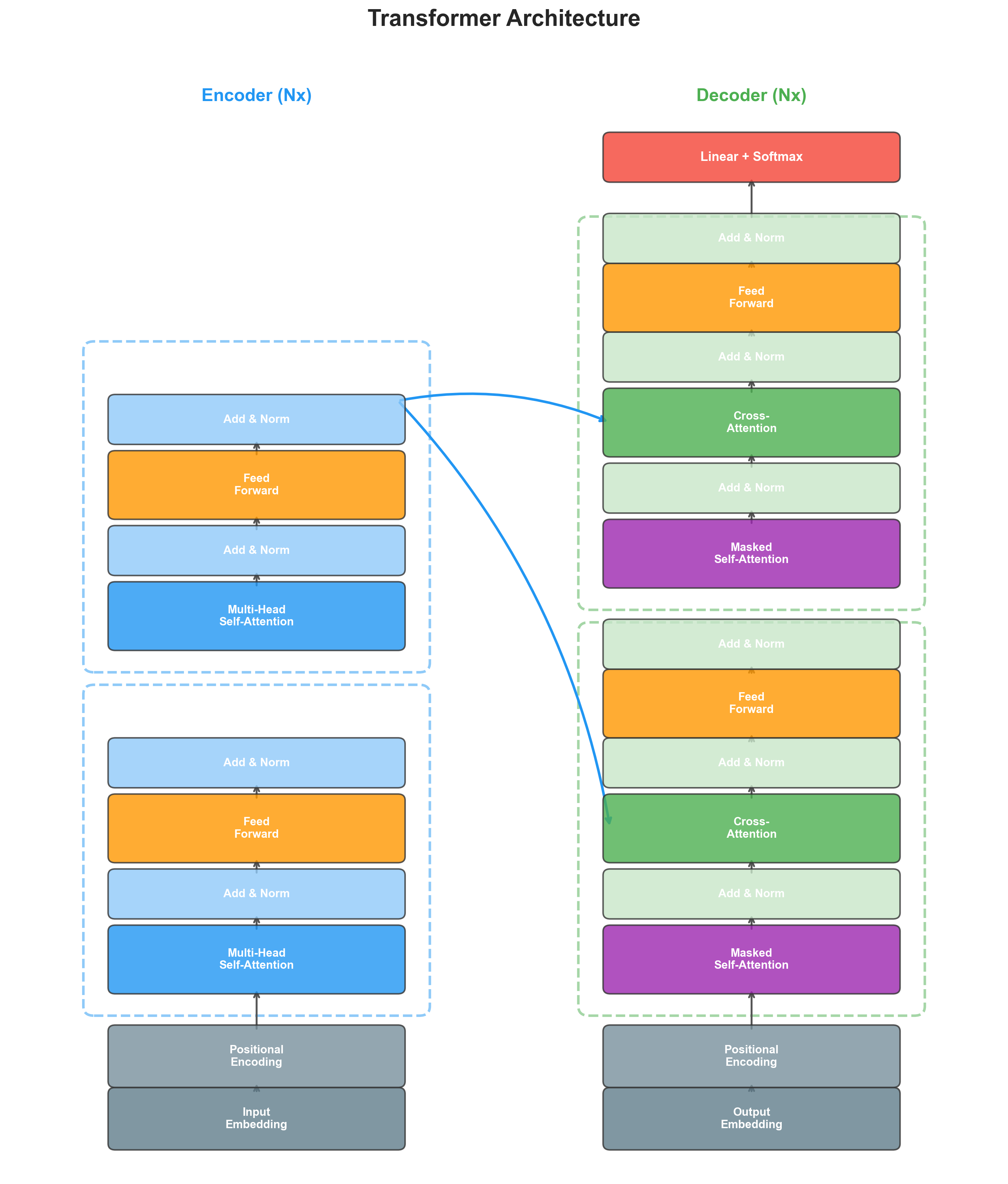
The Architecture at a Glance
The Transformer follows an encoder-decoder structure, but replaces recurrence entirely with attention. Here is the high-level data flow:
- Source tokens are embedded and positionally encoded, then passed through encoder layers
- Target tokens (shifted right) are embedded and positionally encoded, then passed through decoder layers
- Each decoder layer attends to both the target sequence (masked) and the encoder output
- A final linear projection + softmax produces the output distribution over the target vocabulary
My implementation uses:
- attention heads
- encoder and decoder layers
- tokens
- Dropout rate of 0.1
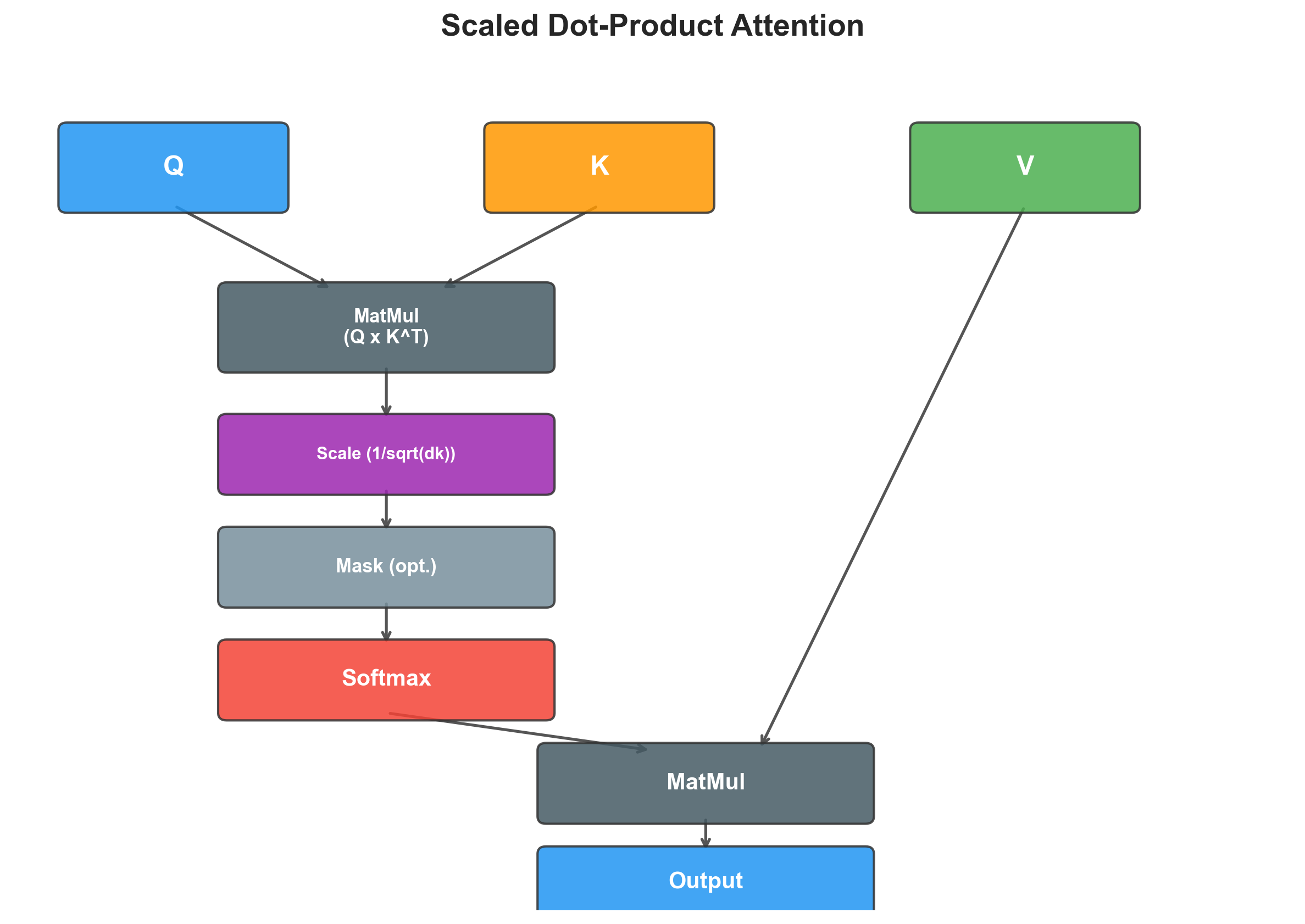
Scaled Dot-Product Attention
The core operation of the Transformer is scaled dot-product attention. Given queries , keys , and values :
where is the dimension per head.
The intuition: each query “asks a question,” each key “advertises what it contains,” and the dot product measures compatibility. The softmax normalizes these into attention weights, which are then used to take a weighted sum of the values.
The scaling factor is critical. Without it, for large , the dot products grow large in magnitude, pushing the softmax into regions with extremely small gradients.
Here is my implementation:
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
self.col_softmax = nn.Softmax(dim=-1)
def forward(self, Q, K, V, mask=None, dropout_fun=None, eps=-1e10):
# Q, K, V: [batch_size, num_heads, maxlen, d_k]
d_k = Q.shape[-1]
# Transpose K and compute scaled dot product
K = K.transpose(-2, -1)
atten = torch.matmul(Q, K) / math.sqrt(d_k)
# Apply mask: fill masked positions with large negative value
if mask is not None:
atten = atten.masked_fill(mask == 0, eps)
# Softmax along the last dimension (columns)
atten = self.col_softmax(atten)
if dropout_fun is not None:
atten = dropout_fun(atten)
# Weighted sum of values
output = torch.matmul(atten, V)
return output, attenA subtle but important detail: the mask fill value is -1e10, not -inf. Using -inf can cause NaN values to propagate through the softmax when an entire row is masked. A very large negative number achieves the same effect (softmax drives it to ~0) without the numerical instability.
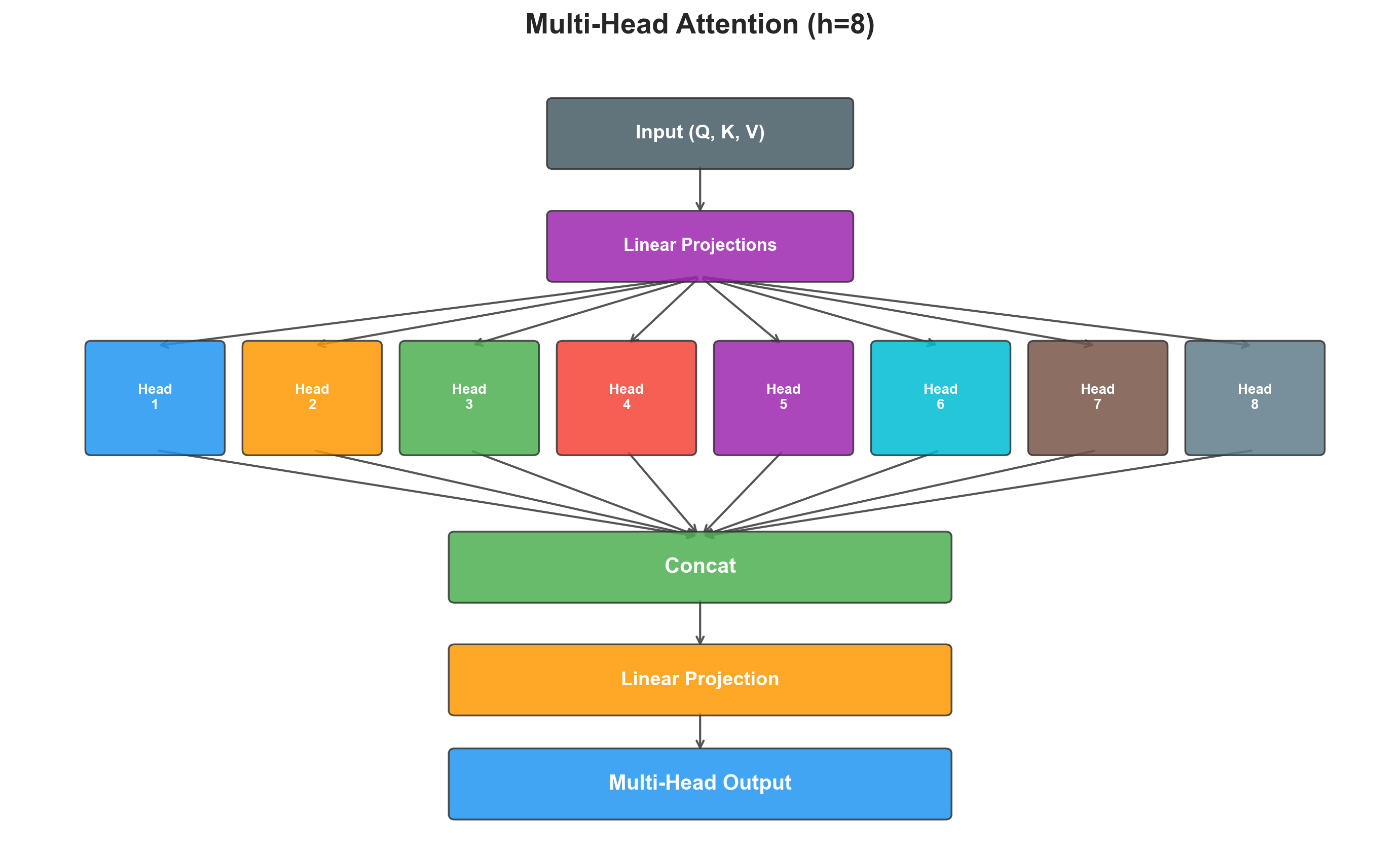
Multi-Head Attention
Rather than performing a single attention function with -dimensional keys, values, and queries, the Transformer projects them into different subspaces and runs attention in parallel:
where .
The key implementation detail is how the heads are managed. Rather than creating separate linear layers, I use a single projection and then reshape:
class MultiHeadedAttention(nn.Module):
def __init__(self, maxlen, d_model, num_heads, dropout):
super(MultiHeadedAttention, self).__init__()
assert d_model % num_heads == 0
self.d_k = d_model // num_heads
self.num_heads = num_heads
self.d_model = d_model
self.W_Q = nn.Linear(d_model, d_model)
self.W_K = nn.Linear(d_model, d_model)
self.W_V = nn.Linear(d_model, d_model)
self.W_O = nn.Linear(d_model, d_model)
self.ScaledDotProdAtten = ScaledDotProductAttention()
self.Dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
Q, K, V = self.W_Q(query), self.W_K(key), self.W_V(value)
# Split into heads: [B, M, d_model] -> [B, H, M, d_k]
Q, K, V = self.split_heads(Q), self.split_heads(K), self.split_heads(V)
if mask is not None:
mask = mask.unsqueeze(1) # broadcast across heads
output, _ = self.ScaledDotProdAtten(Q, K, V, mask, self.Dropout)
# Concatenate heads: [B, H, M, d_k] -> [B, M, d_model]
output = self.join_heads(output)
output = self.W_O(output)
return output
def split_heads(self, x):
B, M, D = x.shape
return x.view(B, -1, self.num_heads, self.d_k).transpose(1, 2)
def join_heads(self, x):
B, H, M, dk = x.shape
return x.transpose(1, 2).contiguous().view(B, -1, self.d_model)The split_heads and join_heads operations are pure reshapes — no parameters, no computation. They just rearrange the tensor so that each head operates on its own -dimensional slice.
Note the mask.unsqueeze(1) in the forward pass. This is important: the mask is typically [B, 1, M] for the source or [B, M, M] for the target. The unsqueeze adds the head dimension, making it [B, 1, 1, M] or [B, 1, M, M], which broadcasts identically across all heads.
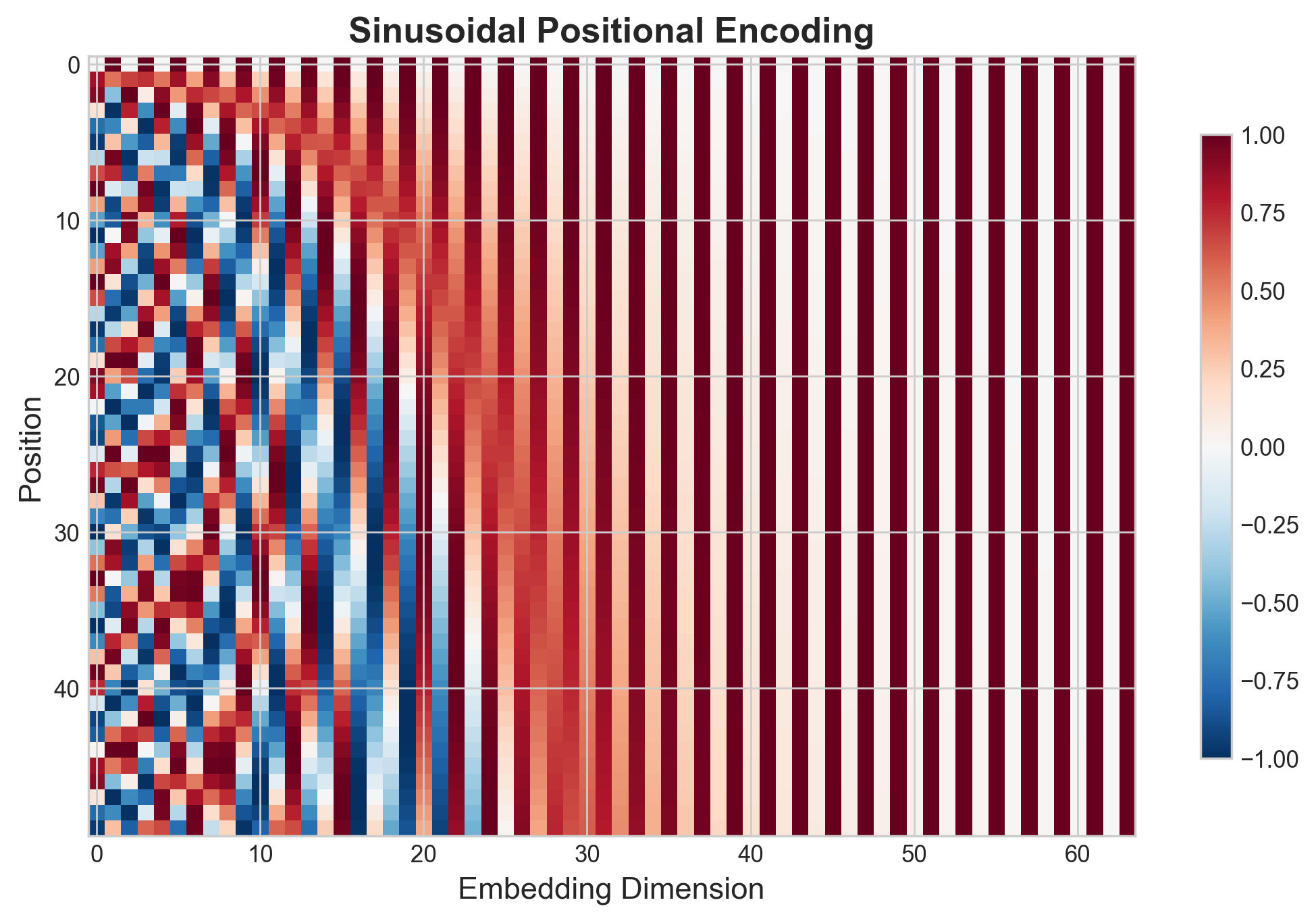
Positional Encoding
Since the Transformer has no recurrence or convolution, it needs positional information injected explicitly. The original paper uses sinusoidal positional encodings:
class PositionalEncoding(nn.Module):
def __init__(self, maxlen, d_model, dropout=0.1):
super(PositionalEncoding, self).__init__()
word_pos = torch.arange(0, maxlen).unsqueeze(1).float()
wk_div = torch.tensor([
[np.power(10000, -(2 * i) / d_model) for i in range(d_model // 2)]
]).float()
pos_enc = torch.zeros((maxlen, d_model)).float()
pos_enc[:, 0::2] = torch.sin(torch.matmul(word_pos, wk_div))
pos_enc[:, 1::2] = torch.cos(torch.matmul(word_pos, wk_div))
pos_enc = pos_enc.unsqueeze(0) # [1, maxlen, d_model]
self.register_buffer("pos_enc", pos_enc)
def forward(self, x):
max_pos_enc_len = x.shape[1]
x = x + self.pos_enc[:, :max_pos_enc_len].requires_grad_(False)
return xTwo things worth noting:
register_buffersaves the encoding in the model’sstate_dictbut does not treat it as a trainable parameter. This is correct — positional encodings are fixed, not learned.requires_grad_(False)on the slice is defensive: it ensures no gradients flow through the positional encoding even if autograd somehow reaches it.
The embedding module combines token embeddings, positional encoding, and dropout:
class TransformerEmbedding(nn.Module):
def __init__(self, vocab_size, d_model, maxlen, dropout=0.1, pad_idx=2):
super(TransformerEmbedding, self).__init__()
self.Embedding_Layer = NormalEmbedding(vocab_size, d_model)
self.Positional_Encoder = PositionalEncoding(maxlen, d_model)
self.Dropout = nn.Dropout(p=dropout)
def forward(self, input_):
output = self.Embedding_Layer(input_)
output = self.Positional_Encoder(output)
return self.Dropout(output)The token embedding is scaled by inside NormalEmbedding. This scaling prevents the positional encoding from dominating the token embedding, since the sinusoidal values range from -1 to 1 while raw embeddings tend to be small.
Position-Wise Feed-Forward Network
Each encoder and decoder layer contains a two-layer feed-forward network applied independently to each position:
This expands the representation from to and then contracts it back:
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff=2048, dropout=0.1):
super(PositionWiseFeedForward, self).__init__()
self.Layer_1 = nn.Linear(d_model, d_ff)
self.Layer_2 = nn.Linear(d_ff, d_model)
self.Dropout = nn.Dropout(p=dropout)
self.relu = nn.ReLU()
def forward(self, input_):
output = self.relu(self.Layer_1(input_))
output = self.Layer_2(self.Dropout(output))
return outputThe “position-wise” name means this is the same linear transformation applied to every position (every token) independently. It is not a single shared MLP applied across the sequence — each position gets the same weights but different inputs.
Encoder
The encoder is identical layers, each containing:
- Multi-head self-attention (with residual connection and layer norm)
- Position-wise feed-forward (with residual connection and layer norm)
I use pre-norm architecture — normalize before the sublayer, then add the residual:
class EncoderLayer(nn.Module):
def __init__(self, maxlen, d_model, d_ff, num_heads, dropout):
super(EncoderLayer, self).__init__()
self.MultiHeadedAttention = MultiHeadedAttention(maxlen, d_model, num_heads, dropout)
self.PositionWiseFeedForward = PositionWiseFeedForward(d_model, d_ff, dropout)
self.mha_LayerNorm = LayerNorm(d_model)
self.pwff_LayerNorm = LayerNorm(d_model)
self.mha_Dropout = nn.Dropout(p=dropout)
self.pwff_Dropout = nn.Dropout(p=dropout)
def forward(self, src_embedding, src_mask):
# Sub-layer 1: Self-attention
mha_input = self.mha_LayerNorm(src_embedding)
mha_output = self.MultiHeadedAttention(mha_input, mha_input, mha_input, src_mask)
mha_output = src_embedding + self.mha_Dropout(mha_output)
# Sub-layer 2: Feed-forward
pwff_input = self.pwff_LayerNorm(mha_output)
pwff_output = self.PositionWiseFeedForward(pwff_input)
pwff_output = mha_output + self.pwff_Dropout(pwff_output)
return pwff_outputThe full encoder stacks of these layers and applies a final layer norm:
class Encoder(nn.Module):
def __init__(self, maxlen, d_model, d_ff, num_heads=8, num_layers=6, dropout=0.1):
super(Encoder, self).__init__()
encoder_layer = EncoderLayer(maxlen, d_model, d_ff, num_heads, dropout)
self.Layers = create_n_deep_copies(encoder_layer, num_layers)
self.LayerNorm = LayerNorm(d_model)
def forward(self, src_embedding, src_mask):
for Layer in self.Layers:
src_embedding = Layer(src_embedding, src_mask)
return self.LayerNorm(src_embedding)I use copy.deepcopy to create the layers. Each layer has its own independent parameters — the deep copy ensures they don’t share weights.
Decoder
The decoder is similar to the encoder but adds a cross-attention sublayer. Each decoder layer has three sublayers:
- Masked self-attention on the target sequence
- Cross-attention where queries come from the decoder and keys/values from the encoder
- Feed-forward network
class DecoderLayer(nn.Module):
def __init__(self, maxlen, d_model, d_ff, num_heads, dropout):
super(DecoderLayer, self).__init__()
self.MaskedMultiHeadedAttention = MultiHeadedAttention(maxlen, d_model, num_heads, dropout)
self.MultiHeadedAttention = MultiHeadedAttention(maxlen, d_model, num_heads, dropout)
self.PositionWiseFeedForward = PositionWiseFeedForward(d_model, d_ff, dropout)
# ... layer norms and dropouts for each sublayer
def forward(self, tgt_embedding, tgt_mask, src_embedding, src_mask):
# Sub-layer 1: Masked self-attention
mask_mha_input = self.mask_mha_LayerNorm(tgt_embedding)
mask_mha_output = self.MaskedMultiHeadedAttention(
mask_mha_input, mask_mha_input, mask_mha_input, tgt_mask
)
mask_mha_output = tgt_embedding + self.mask_mha_Dropout(mask_mha_output)
# Sub-layer 2: Cross-attention (Q=decoder, K=V=encoder)
mha_input = self.mha_LayerNorm(mask_mha_output)
mha_output = self.MultiHeadedAttention(
mha_input, src_embedding, src_embedding, src_mask
)
mha_output = mask_mha_output + self.mha_Dropout(mha_output)
# Sub-layer 3: Feed-forward
pwff_input = self.pwff_LayerNorm(mha_output)
pwff_output = self.PositionWiseFeedForward(pwff_input)
pwff_output = mha_output + self.pwff_Dropout(pwff_output)
return pwff_outputThe cross-attention sublayer is where the decoder “looks at” the source sentence. The query comes from the decoder’s masked self-attention output, but the key and value come from the encoder output. This is how translation information flows from source to target.
Masking
There are two types of masks:
Padding mask: Prevents attention to <PAD> tokens. This is a simple boolean mask:
def create_pad_mask(input_, pad_idx):
# input_: [batch_size, max_len]
# output: [batch_size, 1, max_len]
return (input_ != pad_idx).unsqueeze(-2)Future token mask (causal mask): Prevents the decoder from attending to future positions. This uses an upper triangular matrix:
def create_future_tok_mask(max_len):
fut_mask = torch.triu(torch.ones((1, max_len, max_len), dtype=torch.uint8), diagonal=1)
return (fut_mask == 0)The target mask is the intersection of both: tgt_mask = pad_mask & future_mask. This ensures the decoder can only attend to non-padded tokens at or before the current position.
The Generator (Output Projection)
The generator maps decoder output to vocabulary logits:
class GeneratorLayer(nn.Module):
def __init__(self, vocab_size, d_model):
super(GeneratorLayer, self).__init__()
self.final_projection = nn.Linear(d_model, vocab_size)
def forward(self, input_):
output = self.final_projection(input_)
output = log_softmax(output, dim=-1)
return outputGetting this layer right is crucial — the output must be in log-probability space to match the loss function, a point I return to in the lessons section below.
Putting It All Together
The full Transformer wires everything up:
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, pad_idx,
maxlen, d_model, d_ff, num_heads=8, num_layers=6, dropout=0.1):
super(Transformer, self).__init__()
self.Src_Embeddings = TransformerEmbedding(src_vocab_size, d_model, maxlen, dropout, pad_idx)
self.Tgt_Embeddings = TransformerEmbedding(tgt_vocab_size, d_model, maxlen, dropout, pad_idx)
self.Encoder = Encoder(maxlen, d_model, d_ff, num_heads, num_layers, dropout)
self.Decoder = Decoder(maxlen, d_model, d_ff, num_heads, num_layers, dropout)
self.Generator = GeneratorLayer(tgt_vocab_size, d_model)
def forward(self, src_tkns, src_mask, tgt_tkns, tgt_mask):
src_embeddings = self.Src_Embeddings(src_tkns)
tgt_embeddings = self.Tgt_Embeddings(tgt_tkns)
encoder_output = self.Encoder(src_embeddings, src_mask)
decoder_output = self.Decoder(tgt_embeddings, tgt_mask, encoder_output, src_mask)
logits = self.Generator(decoder_output)
return logitsI added assertion checks throughout the forward pass during development. They verify tensor shapes at every step — a practice I now consider essential for any non-trivial model. Assertions catch shape mismatches immediately instead of letting them propagate into mysterious NaN losses three layers later.
Training on Multi30k
I trained on the Multi30k German-English dataset using torchtext:
- Tokenization: SpaCy (
de_core_news_smfor German,en_core_web_smfor English) - Vocabulary: Built from the training set with special tokens
<SOS>,<EOS>,<PAD>,<UNK> - Batch size: 32
- Optimizer: Adam
- Loss: Label smoothing with KL divergence loss (smoothing = 0.1)
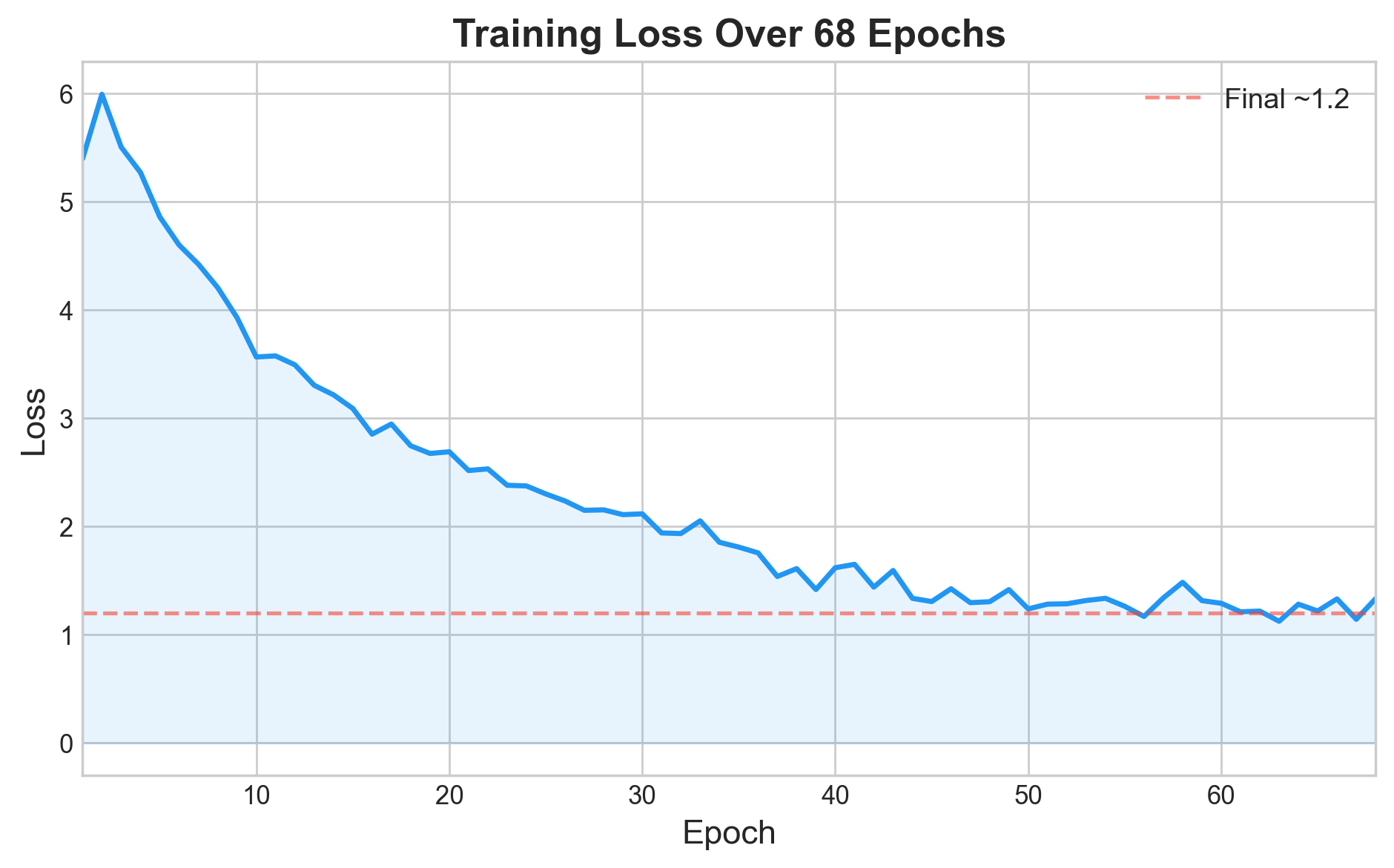
- Epochs: 68
- Initialization: Xavier uniform for all parameters with
dim > 1
The data processing pipeline handles tokenization, numericalization, and padding. Each batch goes through process_batch, which:
- Creates the source padding mask
- Offsets the target by one position (teacher forcing)
- Creates the combined target mask (padding + future token)
Lessons from a Comprehensive Code Audit
Revisiting this code with more experience revealed several areas for improvement. Each one taught me something specific about how Transformers work at the implementation level — the kind of understanding you only get by building the architecture from first principles.
Lesson 1: Loss Functions and Output Spaces Must Agree
During a detailed code review, I identified that the generator layer’s output space must precisely match what the loss function expects. With KLDivLoss, the model must output log-probabilities. If you accidentally pass regular probabilities (values between 0 and 1), the loss computation becomes:
where should be log-probabilities but is instead raw probabilities. The loss surface distorts, gradients point in the wrong directions, and the model trains without improving — a plateau around ~5.4 that never resolves.
The fix is ensuring the generator uses log_softmax rather than softmax. One function call. The lesson is broader: always verify that your loss function and output layer agree on the probability space. This is the kind of issue that will not crash your program — it will silently produce a suboptimal model and send you searching for architectural problems when the real cause is a single function choice.
Lesson 2: Convention Consistency Across Reference Code
When adapting code from tutorials and reference implementations, it is essential to translate everything fully into your own conventions. In my codebase, I used PascalCase for module attributes (self.Encoder, self.Decoder, self.Generator) — a convention that differed from the “Annotated Transformer” reference which used lowercase. When incorporating the greedy decode function, the reference’s model.generator (lowercase) did not match my model.Generator (PascalCase).
The deeper insight: establish a naming convention and enforce it everywhere. Mixing two styles — even between training code and inference code — creates surfaces for silent mismatches that only appear during evaluation, never during training.
Lesson 3: Positional Arguments with Multiple Tensor Parameters
The decoder’s forward method takes four tensors: tgt_embedding, tgt_mask, src_embedding, src_mask. When calling this function, it is straightforward to swap two arguments — especially tgt_mask and encoder_output. Since PyTorch does not type-check tensor semantics (both are tensors with compatible-ish shapes), a swap does not crash. It produces garbled translations.
After discovering this during testing, I adopted two practices. First, shape assertions at every boundary:
assert tgt_mask.size() == (batch_size, self.maxlen-1, self.maxlen-1), \
f"tgt_mask size should be {(batch_size, self.maxlen-1, self.maxlen-1)}, got {tgt_mask.size()}"Second, using keyword arguments for any function that takes more than two tensors. Positional arguments are a liability when the parameters are semantically distinct but structurally similar.
Lesson 4: Framework API Precision
PyTorch provides multiple casting methods — .type(), .to(), .float(), .int() — but .as_type() is not among them. I had confused it with NumPy’s .astype(). When moving between frameworks, it pays to double-check the API. A good practice is to use .to(dtype) consistently, since it works for both device and dtype conversions.
Greedy Decoding
At inference time, the model generates one token at a time using greedy decoding:
def greedy_decode(model, src, src_mask, max_len, start_symbol):
memory = model.encode(src, src_mask)
ys = torch.zeros(1, 1).fill_(start_symbol).type_as(src.data)
for i in range(max_len - 1):
out = model.decode(
ys, create_future_tok_mask(ys.size(1)).type_as(src.data), memory, src_mask
)
prob = model.Generator(out[:, -1])
_, next_word = torch.max(prob, dim=1)
next_word = next_word.data[0]
ys = torch.cat(
[ys, torch.zeros(1, 1).type_as(src.data).fill_(next_word)], dim=1
)
return ysAt each step: encode the source once, then iteratively decode by feeding the growing target sequence back through the decoder. The future token mask grows with each new token, ensuring the decoder only sees what it has generated so far.
Results and Reflections
After training for 68 epochs, the model produced reasonable German-to-English translations on Multi30k’s test set. Multi30k is a relatively simple dataset — short, concrete image descriptions — so it is a good testbed for verifying that an implementation is architecturally sound.
The quantitative metrics are less important to me than what I learned building this:
-
Shape assertions are not optional. I added assertions for every tensor at every layer boundary. They cost nothing at training time (you can disable them with
model.eval_run = True) and they catch issues that would otherwise manifest as “the model just doesn’t learn.” -
The loss function and the output layer must agree. This sounds obvious, but it is remarkably easy to get wrong. If you use
KLDivLoss, your model must output log-probabilities. If you useCrossEntropyLoss, your model should output raw logits (it applies log-softmax internally). -
Adapt reference code fully into your conventions. Two of the refinements I identified came from mixing reference code that used different conventions than my own. When you incorporate code from a tutorial, translate it completely — do not blend two styles.
-
Pre-norm vs. post-norm matters. I use pre-norm (normalize before the sublayer), which tends to train more stably than post-norm (normalize after). If you are getting training instability, this is worth checking.
-
The modular structure pays off. By splitting the Transformer into separate files for attention, feed-forward, encoder layer, decoder layer, masking, etc., each component could be tested and understood independently. The final integration was straightforward once each piece worked on its own.
Building a Transformer from scratch is the best way I know to understand the architecture deeply. The paper describes it; the code forces you to confront every detail — every transpose, every unsqueeze, every mask shape. I recommend it to anyone who wants to move beyond “I know what attention is” to “I know exactly how attention flows through a 6-layer encoder-decoder stack.”
The full implementation lives in my Transformer repository , with separate modules for each component.